| 5.3. Internal file formats | ||
|---|---|---|
 |
Chapter 5. Formats | 
|
| 5.3. Internal file formats | ||
|---|---|---|
|
|
Chapter 5. Formats |
|
Please let us know if you find any other internal files, figure out formats of any internal files or find out what unknown parts of the files below do. Any and all contributions will be fully attributed and, if appropriate, co-copyright given.
In this section, where the description of a file says that an item is an offset into another file, that file may be located in the same CHM, or it may be located in an accompanying CHI file.
The different types of ITSF files contain different internal files. The list below indicates which file types contain which internal files:
/#ITBITS, /#SYSTEM, /#IDXHDR, /#STRINGS, /#TOCIDX, /#TOPICS, /#URLSTR, /#URLTBL, /#WINDOWS, /$OBJINST, /$WWAssociativeLinks/BTree, /$WWAssociativeLinks/Data, /$WWAssociativeLinks/Map, /$WWAssociativeLinks/Property, /$WWKeywordLinks/BTree, /$WWKeywordLinks/Data, /$WWKeywordLinks/Map, /$WWKeywordLinks/Property
/#ITBITS, /#SYSTEM, /#IDXHDR, /#STRINGS, /#TOCIDX, /#TOPICS, /#URLSTR, /#URLTBL, /#IVB, /#SUBSETS, /#WINDOWS, /$FIftiMain, /$OBJINST, /$WWAssociativeLinks/BTree, /$WWAssociativeLinks/Data, /$WWAssociativeLinks/Map, /$WWAssociativeLinks/Property, /$WWKeywordLinks/BTree, /$WWKeywordLinks/Data, /$WWKeywordLinks/Map, /$WWKeywordLinks/Property
/$FIftiMain, /$OBJINST, /$TitleMap
/$OBJINST, /$HHTitleMap, /$WWAssociativeLinks/BTree, /$WWAssociativeLinks/Data, /$WWAssociativeLinks/Map, /$WWAssociativeLinks/Property, /$WWKeywordLinks/BTree, /$WWKeywordLinks/Data, /$WWKeywordLinks/Map, /$WWKeywordLinks/Property
windowtype, AdvSearchUI/Keywords, AdvSearchUI/Properties, Bookmarks/v1/Count, Bookmarks/v1/n/Topic, Bookmarks/v1/n/Url
#GRPINF (see helpdeco docs by Manfred Winterhoff for a possible function), #INFOTYPES (probably will be output when MS implements information types), #URLS (probably a previous incarnation of the #URLTBL + #URLSTR combination), #BSSC (8 bytes, based on something I saw in KeyTools.exe it might contain the version of RoboHelp used to create the CHM. If you have RoboHelp please check this out & be sure to send in your chm.)
The files I have seen so far have been empty or filled with zero BYTEs so who knows. My guess is that it has something to do with information types. The file where it had a non-zero size (12 zero BYTEs in VOICESDK.CHI from the MSDN) also had a non-zero #SYSTEM code 15 (Information type checksum) entry of 0xFFFFFFFF.
The #SYSTEM file begins with a DWORD, which is a version number. It is 2 in files compiled with Compatibility set to "1.0" or 3 in files compiled with Compatibility set to 1.1 or later. Other values have not been found. It is followed by #SYSTEM entries to the EOF, which have the following format:
Table 5.1. The format of #SYSTEM entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | code - see below for values & meanings |
| 2 | WORD | length of data |
| 4 | BYTEs | data |
In the below list of the different codes the order of the codes in the #SYSTEM file is 10, 9, 4, 2, 3, 16, 6, (5,0,1 or 0,1,5 - haven't been able to make files with all three), 7, 11, 12, 13, 14, 8 and lastly 15.
Table 5.2. An explanation for each of the #SYSTEM codes.
| Code[a] | Explanation | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Value of Contents file in the [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
| 1 | Value of Index file in the [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
| 2 | Value of Default topic in the [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
| 3 | Value of Title in the [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
| 4 |
28 (HHA Version 4.72.7294 and earlier) or 36 (HHA Version 4.72.8086 and later) byte structure: Table 5.3. The format of the code 4 #SYSTEM entry.
|
|||||||||||||||||||||||||||
| 5 | Value of Default Window in the [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
| 6 | Value of Compiled file in the [OPTIONS] section of the HHP file. This is the lowercase of the stem of the CHM file name. If the name of the CHM is ..\bar\foo\ FOO-Bar . chm jimmy is a poo-bum then this will be foo-bar . NT | |||||||||||||||||||||||||||
| 7 | [a]DWORD present in files with Binary Index turned on. The entry in the #URLTBL file that points to the sitemap index had the same first DWORD. | |||||||||||||||||||||||||||
| 8 |
Rare. VOICESDK.CHM & CHI and WOSA.CHI from the MSDN have one. The abbreviations and explanations seem to be the same in WOSA.CHI & VOICESDK.CHM, except for 2 mistakes (one in VOICESDK.CHM & one in WOSA.CHI) that seem to be created by bugs in the compiler. Both were compiled by the same version of HHA (4.72.8086), so perhaps this version has some weird bug. Each entry is 16 BYTEs: Table 5.4. The format of the code 8 #SYSTEM entry.
|
|||||||||||||||||||||||||||
| 9 | The version/program that the CHM was compiled by - shown in the version dialog as Compiled with %s where %s is what is in this entry of the #SYSTEM file. If compiled with the MS HTML Help Author dll then it will be something like HHA Version 4.74.8702. It comes directly from the resource strings of HHA.dll (I saw it there in Unicode and successfully altered it). Beware that the text control in the version dialog that displays it is only so big and in some cases the string won't be displayed, & in other cases only part, depending apon the effect of wrapping, so if you write a compiler, be sure to test it and use a short name and version. Usually NT, but HH won't crash if it isn't. | |||||||||||||||||||||||||||
| 10 | time_t timestamp (DWORD). Derived from GetLocalTime. Not sure of the conversion yet. | |||||||||||||||||||||||||||
| 11 | [a]DWORD present in files with Binary TOC turned on. The entry in the #URLTBL file that points to the sitemap contents has the same first DWORD. | |||||||||||||||||||||||||||
| 12 | [a]DWORD. Number of information types. | |||||||||||||||||||||||||||
| 13 | [a]The #IDXHDR file contains exactly the same bytes. See below for more info | |||||||||||||||||||||||||||
| 14 | Rare. The ones I saw were from MS Word 2000. My guess is that it is an MSOffice extension (or maybe not) that overrides the names & window types of the navigation tabs. DWORD number of windows to override, 2 ANSI/UTF-8 NT strings for each window. The first is the text for the tab & the second is probably the name of the window type to use. (eg 2, &Answer Wizard\0MsoHelpAWDlg\0&Index\0MsoHelpKeyDlg\0) These are from the Custom tab variables of the [OPTIONS] section of the HHP file. The resources from MSOHELP.EXE have a weird .reg file that gives the CLSIDs involved in the provision of these dialogs. | |||||||||||||||||||||||||||
| 15 | [a]DWORD. Information type checksum. Unknown algorithm & data source. | |||||||||||||||||||||||||||
| 16 | Value of Default Font in [OPTIONS] section of the HHP file. NT | |||||||||||||||||||||||||||
|
[a] Code 17 to code 65535 have not yet been seen. Please let us know if you see these. [a] Not present in files compiled with Compatibility set to 1.0. | ||||||||||||||||||||||||||||
This has exactly the same bytes as the code 13 entry in the #SYSTEM file and is 4096 bytes long.
Table 5.5. The format of the #IDXHDR file.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | char[4] | T#SM |
| 4 | DWORD | Unknown timestamp/checksum |
| 8 | DWORD | 1 (unknown) |
| 0xC | DWORD | Number of topic nodes including the contents & index files |
| 0x10 | DWORD | 0 (unknown) |
| 0x14 | DWORD | Offset in the #STRINGS file of the ImageList param of the "text/site properties" object of the sitemap contents (0/-1 = none) |
| 0x18 | DWORD | 0 (unknown) |
| 0x1C | DWORD | 1 if the value of the ImageType param of the "text/site properties" object of the sitemap contents is Folder. 0 otherwise. |
| 0x20 | DWORD | The value of the Background param of the "text/site properties" object of the sitemap contents |
| 0x24 | DWORD | The value of the Foreground param of the "text/site properties" object of the sitemap contents |
| 0x28 | DWORD | Offset in the #STRINGS file of the Font param of the "text/site properties" object of the sitemap contents (0/-1 = none) |
| 0x2C | DWORD | The value of the Window Styles param of the "text/site properties" object of the sitemap contents |
| 0x30 | DWORD | The value of the ExWindow Styles param of the "text/site properties" object of the sitemap contents |
| 0x34 | DWORD | Unknown. Often -1. Sometimes 0. |
| 0x38 | DWORD | Offset in the #STRINGS file of the FrameName param of the "text/site properties" object of the sitemap contents (0/-1 = none) |
| 0x3C | DWORD | Offset in the #STRINGS file of the WindowName param of the "text/site properties" object of the sitemap contents (0/-1 = none) |
| 0x40 | DWORD | Number of information types. |
| 0x44 | DWORD | Unknown. Often 1. Also 0, 3. |
| 0x48 | DWORD | Number of files in the [MERGE FILES] list. |
| 0x4C | DWORD | Unknown. Often 0. Non-zero mostly in files with some files in the merge files list. |
| 0x50 | DWORD[1004] | List of offsets in the #STRINGS file that are the [MERGE FILES] list. Zero terminated, but don't count on it. |
This file contains information on the window types in the CHM. It has the following format:
Table 5.6. The format of the #WINDOWS header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Number of entries in the file |
| 4 | DWORD | Size of each of the entries in the file (188 or 196) |
| 8 | #WINDOWS entries to the EOF | |
#WINDOWS entries are basically HH_WINTYPE structures as specified in htmlhelp.h. Note the first DWORD can be used to specify different versions of this structure. Also note that the HHW docs show a different structure to htmlhelp.h. Therefore many CHM files need to be surveyed to find structures with sizes other than 188 or 196. In the description of #WINDOWS entries below, Arg n means that that item is argument n of the window definition in the HHP file, either converted to a DWORD or to an offset in the indicated file:
Table 5.7. The format of each #WINDOWS entry.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Size of the entry (188 in CHMs compiled with Compatibility set to 1.0, 196 in CHMs compiled with Compatibility set to 1.1 or later) |
| 4 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "BOOL fUniCodeStrings; // IN/OUT: TRUE if all strings are in UNICODE" |
| 8 | DWORD | Arg 0. Offset in #STRINGS file. |
| 0xC | DWORD | Which window properties are valid & are to be used for this window. See the table below. |
| 0x10 | DWORD | Arg 10. |
| 0x14 | DWORD | Arg 1. Offset in #STRINGS file. |
| 0x18 | DWORD | Arg 14. |
| 0x1C | DWORD | Arg 15. |
| 0x20 | RECT | Arg 13. Order left, top, right & bottom. |
| 0x30 | DWORD | Arg 16. |
| 0x34 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HWND hwndHelp; // OUT: window handle" |
| 0x38 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HWND hwndCaller; // OUT: who called this window" |
| 0x3C | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HH_INFOTYPE* paInfoTypes; // IN: Pointer to an array of Information Types" |
| 0x40 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HWND hwndToolBar; // OUT: toolbar window in tri-pane window" |
| 0x44 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HWND hwndNavigation; // OUT: navigation window in tri-pane window" |
| 0x48 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "HWND hwndHTML; // OUT: window displaying HTML in tri-pane window" |
| 0x4C | DWORD | Arg 11. |
| 0x50 | BYTE[16] | 0 (unknown) - but htmlhelp.h indicates that this is a RECT that is "RECT rcHTML; // OUT: HTML window coordinates" & the HHW docs say "Specifies the coordinates of the Topic pane." |
| 0x60 | DWORD | Arg 2. Offset in #STRINGS file. |
| 0x64 | DWORD | Arg 3. Offset in #STRINGS file. |
| 0x68 | DWORD | Arg 4. Offset in #STRINGS file. |
| 0x6C | DWORD | Arg 5. Offset in #STRINGS file. |
| 0x70 | DWORD | Arg 12. |
| 0x74 | DWORD | Arg 17. |
| 0x78 | DWORD | Arg 18. |
| 0x7C | DWORD | Arg 19. |
| 0x80 | DWORD | Arg 20. |
| 0x84 | BYTE[20] | 0 (unknown) - but htmlhelp.h indicates that this is "BYTE tabOrder[HH_MAX_TABS + 1]; // IN/OUT: tab order: Contents, Index, Search, History, Favorites, Reserved 1-5, Custom tabs" |
| 0x98 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "int cHistory; // IN/OUT: number of history items to keep (default is 30)" |
| 0x9C | DWORD | Arg 7. Offset in #STRINGS file. |
| 0xA0 | DWORD | Arg 9. Offset in #STRINGS file. |
| 0xA4 | DWORD | Arg 6. Offset in #STRINGS file. |
| 0xA8 | DWORD | Arg 8. Offset in #STRINGS file. |
| 0xAC | BYTE[16] | 0 (unknown) - but htmlhelp.h indicates that this is a RECT that is "RECT rcMinSize; // Minimum size for window (ignored in version 1)" |
| Everything after here is only present in CHMs compiled with Compatibility set to 1.1 or later. | ||
| 0xBC | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "int cbInfoTypes; // size of paInfoTypes;" |
| 0xC0 | DWORD | 0 (unknown) - but htmlhelp.h indicates that this is "LPCTSTR pszCustomTabs; // multiple zero-terminated strings" |
Table 5.8. Flags used to specify which values are valid.
| Value[a] | Valid property |
|---|---|
| 0x00000002 | Navigation pane style. |
| 0x00000004 | Window style flags. |
| 0x00000008 | Window extended style flags. |
| 0x00000010 | Initial window position. |
| 0x00000020 | Navigation pane width. |
| 0x00000040 | Window show state. |
| 0x00000080 | Info types. |
| 0x00000100 | Buttons. |
| 0x00000200 | Navigation Pane initially closed state. |
| 0x00000400 | Tab position. |
| 0x00000800 | Tab order. |
| 0x00001000 | History count. |
| 0x00002000 | Default Pane. |
[a] The rest of the values either do nothing or are unknown. Please let us know if you find out what they are. | |
This file is a list of ANSI/UTF-8 NT strings. The first is just a NIL character so that offsets to this file can specify zero & get a valid string. The strings are sliced up into blocks that are 4096 bytes in length. If a string crosses the end of a block then it will be cut off without a NT and repeated in full, with a NT, at the start of the next block. For eg "To customize the appearance of a contents file" might become "To customize the <block ending>To customize the appearance of a contents file" when there are 17 bytes left at the end of the block. The last block will be smaller than 4096 bytes if the strings do not fill it up.
The strings are in this order; "", [WINDOWS] (Arg 0, Arg 1, Arg 7, Arg 9, Arg 2, Arg 3, Arg 4, Arg 5, Arg 6, Arg 8) no. n..., Contents_0_Entry_title, Index_0_Keyword, Contents_Image_file, Contents_Font, Contents_Default_frame, Contents_Default_window, [MERGE FILES] no. n...
Present in files with a non-empty contents file, when Binary TOC is on and Compatibility is set to 1.1 or later.
This file is made up of 0x1000 byte blocks, but this is only apparent because of extra bytes interrupting what would otherwise be a stream of 20/28 byte structs. If the other parts (DWORDs & 16 byte structs) didn't fit into these blocks then presumably this would show up in the other parts too.
The first block is the header:
Table 5.9. The format of the #TOCIDX header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | 4096/header length/offset of no. 1 below |
| 4 | DWORD | offset of no. 3 below |
| 8 | DWORD | number of no. 3 below |
| 0xC | DWORD | offset of no. 2 below |
| 0x10 | BYTE[4080] | 0 (unknown) |
The header is followed by the following different types of structs in the specified order:
20/28 byte structs (pages/books)
list of DWORDs pointing into the #TOPICS file
16 byte structs - links above stuff
First all the top level books/pages, then the next level, then the next & so on
Table 5.10. 20/28 byte structures
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | 0 (unknown) |
| 2 | WORD | Unknown |
| 4 | DWORD | Seems to be a bit field: 0x2 is whether or not New is turned on, 0x4 is set when the entry is a book/has children and 0x8 is set when the entry has a Local value. The other bits are unknown (0x1, 0x40, 0x100 are sometimes set on books). |
| 8 | DWORD | Unknown. In some cases it is an index into the #TOPICS file of the entry containing offsets to the title & filename. |
| 0xC | DWORD | Offset to the parent book. |
| 0x10 | DWORD | Offset to the next book/page in the current book/page. |
| The next two DWORDs are only present in books (28 byte structs) | ||
| 0x14 | DWORD | Offset to the first child of the book. |
| 0x18 | DWORD | 0 (unknown) |
Table 5.11. 16 byte structures
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Offset into no. 1 above. |
| 4 | DWORD | Some kind of sequence number that is incremented by one and starts at 666. I swear :) |
| 8 | DWORD | Offset into no. 2 above. Can contain RAM litter. |
| 0xC | DWORD | Index in #TOPICS file of the entry containing offsets to the title & filename. Can contain RAM litter. |
![[Note]](note.png) |
Note |
|---|---|
Note that an index into this file should be multiplied by 16 to get the offset of the entry. | |
An index into this file can be converted to an offset in the #URLTBL file, without reading this file using the following formula: offset = (index%341)*12 + index/341*4096
This file contains information on the topics present.
Each entry has the following format.
Table 5.12. The format of the #TOPICS file entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Offset into the tree in the #TOCIDX file. |
| 4 | DWORD | Offset in #STRINGS file of the contents of the title tag or the Name param of the file in question. -1 = no title. |
| 8 | DWORD | Offset in #URLTBL of entry containing offset to #URLSTR entry containing the URL. |
| 0xC | WORD | 2 indicates not in contents, 6 indicates that it is in the contents, 0/4 something else (unknown) |
| 0xE | WORD | 0, 2, 4, 8, 10, 12, 16, 32 (unknown) |
This file is made up of 0x4000 byte blocks. If the last block is not filled then it will be smaller than 0x4000 bytes. The free space at the end of the blocks is filled with NUL bytes. The blocks contain the following elements one after another:
An unknown BYTE. So far this has been 0, 0x42 and in spechsdk.chi it was 0x49. Does not indicate presence/absence of URL/FrameName strings.
This is followed by pairs of URL, FrameName strings (both NT) from the HHC.
Then come all the Local strings from the HHC:
Table 5.13. The format of the #URLSTR entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Offset of the URL for this topic. |
| 4 | DWORD | Offset of the FrameName for this topic. |
| 8 | ANSI/UTF-8 NT string that is the Local for this topic. |
There is one way to tell where the end of the URL/FrameName pairs occurs: Repeat the following: read 2 DWORDs and if both are less than the current offset then this is the start of the Local strings else skip two NT strings.
An offset in this file can be converted to an index into the #TOPICS file, without reading this file using the following formula: index = ((offset%4096)+((offset/4096)*4096-4))/12
Each 0x1000 byte block has the following format.
Table 5.14. The format of the #URLTBL blocks.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD[3][341] | 341 entries. 12 bytes each. |
| 0xFFC | DWORD |
4096 (unknown) Possibly the length of the block? That MS would pull this kind of shit is really annoying; they should have just put all the entries one after another, not stuffed in an arbitrary DWORD after every 4092 bytes. From this and other blockness I guess they are optimizing for the Wintel platform. |
Each entry has the following format.
This is basically the [ALIAS] section of the HHP file.
The #IVB file begins with a DWORD indicating the total size of all the #IVB entries, which then follow that DWORD.
#IVB entries have the following format.
This file is present when the [SUBSETS] section is present in the HHP file.
Table 5.17. The format of the #SUBSETS header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | 0 (unknown) |
| 2 | WORD | Number of bytes taken up by the subset entries. |
The subset entries currently seem to be garbage left over from previous usage of the same memory locations. Based on the number of bytes per non-whitespace line in the [SUBSETS] section each subset entry is 12 BYTEs in length.
I would like to acknowledge Jed Wing for reverse-engineering this file and Razvan Cojocaru for pointing out clarity issues in this section.
This file stores information for the full-text search function of HTML Help. It prevents the need for viewers of CHM files to search each and every topic in the CHM to find words or phrases. This speeds up searching considerably, since the index that this file stores, contains data on which words occur in which files and at which locations.
This file will be empty when Full-text search has been turned off or when no files have been indexed. The CHM compiler will only index those files that contain .h in their names. All word sorting, processing and storage is done case-insensitively and is not case-preserving. If you have a word longer than 99 characters in a HTML file then it seems the indexing routines will die during indexing of that file and then skip on to the next one.
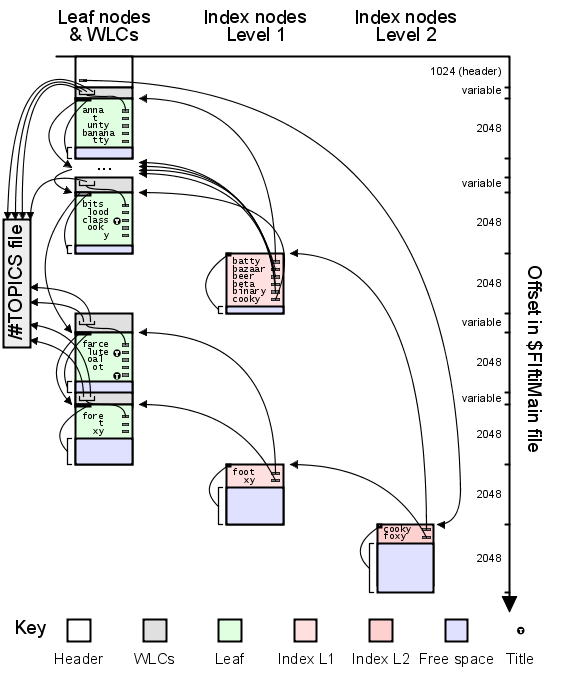
The full-text search data is structured as a tree that is more similar to the ITSP directory than the BTree file. The file begins with a header. This is followed by index nodes, leaf nodes and word location codes (WLCs). The index and leaf nodes are a fixed size (specified in the header) and the WLCs are variably sized (specified in the leaf nodes). There is a WLC block just before each leaf node and the pairs of WLC blocks and leaf nodes are interspersed with index nodes. Index nodes only point to nodes (index or leaf) that are further down the tree and at the same time located colser to the start of the file. The index nodes are directly after the last of their child nodes in the file. The structure of this format is best explained by the following diagram of a ficticious $FIftiMain file. For a more extensive set of examples see the example section
This file makes use of two different ways of encoding integers in variable length fields; the so called scale and root method and a variant of the ENCINT method used in the PMGL/PMGI directory chunks from the ITSF format. For the ENCINTs in this file the bytes are stored least significant first (little endian), whereas in the PMGL/PMGI chunks they are stored most significant first (big endian).
For CHM viewers that want to quickly find out which files a word is in, the procedure is as follows; read the header, seek to the root index node, search the root index node for a word that is less than or equal to the desired, descend to the next index level, repeat the previous two steps as many times as the tree is deep, then search the resulting leaf node until the desired word is found, read the correct part of the WLCs for that leaf node and extract the topic numbers for that word. Once all the topic numbers have been found for the desired words, make sure there are no duplicates and extract the titles and urls from the #TOPICS, #URLTBL, #URLSTR and #STRINGS files.
For sample code for decoding $FIftiMain files, see chmdeco, xCHM or dump_fiftimain.c from the old html versions of this specification.
The file begins with a header that is 0x400 bytes in length:
Table 5.18. The format of the $FIftiMain header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | BYTE[4] | 0x00 0x00 0x28 0x00 (unknown) |
| 4 | DWORD | Number of HTML files indexed after any automatic splitting. |
| 8 | DWORD | Offset to the single leaf node (if there are no index nodes), or the root index node of the tree (if there are any index nodes). This will be 4096 less than the file length. |
| 0xC | DWORD | 0 (unknown) |
| 0x10 | DWORD | The number of leaf nodes in the file. |
| 0x14 | DWORD | Same as the value at offset 8. |
| 0x18 | WORD | How many nodes deep the tree is: e.g. 1 if only a single leaf node, 2 if there is a single index node to index among the leaf nodes, 3 if there are 2 levels of index nodes. |
| 0x1A | DWORD | 7 (unknown) |
| 0x1E | BYTE | Scale for encoding of the document index in the WLCs |
| 0x1F | BYTE | Root size for encoding of the document index in the WLCs |
| 0x20 | BYTE | Scale for encoding of the code count in the WLCs |
| 0x21 | BYTE | Root size for encoding of the code count in the WLCs |
| 0x22 | BYTE | Scale for encoding of the location codes in the WLCs |
| 0x23 | BYTE | Root size for encoding of the location codes in the WLCs |
| 0x24 | BYTE[10] | 0 (unknown) |
| 0x2E | DWORD | Size in bytes of each of the leaf and index nodes (4096). |
| 0x32 | DWORD | 0/1 (unknown) |
| 0x36 | DWORD | Word index of the last duplicate. |
| 0x3A | DWORD | Character index of the last duplicate. From the first character of the first word. The whitespace after tags is not included. & type things are counted as one character. Line endings are not counted in this. |
| 0x3E | DWORD | Length of the longest word in the list not including NT (maximum of 99). |
| 0x42 | DWORD | Number of words including duplicates. |
| 0x46 | DWORD | Number of words not including duplicates. |
| 0x4A | DWORD | The total length of all the words including duplicates is this DWORD plus the next one. It is unknown how the split is performed. |
| 0x4E | DWORD | This one is usually smaller than the previous one. |
| 0x52 | DWORD | Total length of all the words not including duplicates. |
| 0x56 | DWORD | Length of unused/null bytes at the end of the word block (if only 1 block, more than total if > 1 block - possibly some free space in WLC blocks). |
| 0x5A | DWORD | 0 (unknown) |
| 0x5E | DWORD | One less than the number of HTML files indexed (not entirely sure). |
| 0x62 | BYTE[24] | 0 (unknown) |
| 0x7A | DWORD | Windows code page identifier (usually 1252 - Windows 3.1 US (ANSI)) |
| 0x7E | DWORD | LCID from the HHP file. |
| 0x82 | BYTE[894] | 0 (unknown) |
The index nodes begin with a WORD indicating the length of free space at the end of the node. This is followed by the entries, which fill up as much of the index node as possible.
Table 5.19. Index node entries
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | BYTE | One more than the length of the word/partial word in this entry. |
| 1 | BYTE | Position in the word where characters are placed. |
| 2 | BYTEs | Length-1 bytes make up the word or part of the word. Not NT |
| +0 | DWORD | Offset of the leaf node whose last entry is this word. |
| +4 | WORD | 0 (unknown) |
The leaf nodes begin with a short header, which is followed by entries:
Table 5.20. Leaf node header
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Offset to the next leaf node. 0 if this is the last leaf node. |
| 4 | WORD | 0 (unknown) |
| 6 | WORD | Length of free space at the end of the current leaf node. |
Table 5.21. Leaf node entries
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | BYTE | Length of the word/partial word in this entry plus one. Maximum of 100. |
| 1 | BYTE | Position in the word where characters are placed. |
| 2 | BYTEs | Length-1 bytes make up the word or part of the word. Maximum of 99 BYTEs. Not NT |
| +0 | BYTE | Context (0 for body tag, 1 for title tag, other values are unknown) |
| +1 | ENCINT | Number of WLC entries. |
| +0 | DWORD | Offset in this file of the WLC entries for this word. |
| +4 | WORD | 0 (unknown) |
| +6 | ENCINT | Number of bytes used by the WLC entries for this word. |
Each WLC block is made up of bits packed as tightly as possible and is right-padded with 0s to a full byte. The fields are encoded as the scale and root variable-length integer format described below, with the parameters taken from the initial header. "Delta coding" is also used in a couple of places to reduce the size of the codes -- that is, the first value is stored verbatim, and subsequent values are stored as a delta or difference from the previous value.
Table 5.22. WLC entries
| Encoding(s) | Name/Comment |
|---|---|
| s/r and delta (across the various entries for a single word) | Document index. Indicates in which document this entry is for by way of an index into the #TOPICS file. |
| s/r | Code count. The number of times that the word this entry specifies is used in the specified topic. |
| s/r and delta (within each WLC entry) | Location codes. A list of word indices (zero based) where this word occurs in the specified topic. |
The scale and root method of integer encoding needs two parameters, which I'll call s (scale) and r (root size). In the context of $FIftiMain files, s always appears to be '2', but any other power of 2 could also work (and might be used in some rare cases).
The integer is encoded as two parts, p (prefix) and q (actual bits). p determines how many bits are stored, as well as implicitly determining the high-order bit of the integer. To encode an integer, p starts out as a single 0. If the integer fits in r bits, you're done. If the integer fits in r+1 bits (i.e. r-th bit is set, counting from 0), prepend a 1 to the p and store the low r bits of the integer in q. Otherwise, while the integer does not fit in the allotted space, prepend a bit to p, and increase the size of q by one bit. It's hard to see from the description, but an example will make it more clear. Using s=2, r=3:
Table 5.23. Example of scale and root encoding
| Value | p | q |
|---|---|---|
| 0 | 0 | 000 |
| 1 | 0 | 001 |
| 2 | 0 | 010 |
| 7 | 0 | 111 |
| 8 | 10 | 000 |
| 9 | 10 | 001 |
| 10 | 10 | 010 |
| 15 | 10 | 111 |
| 16 | 110 | 0000 |
| 17 | 110 | 0001 |
| 18 | 110 | 0010 |
| 30 | 110 | 1110 |
| 31 | 110 | 1111 |
| 32 | 1110 | 00000 |
| 33 | 1110 | 00001 |
| 34 | 1110 | 00010 |
| 62 | 1110 | 11110 |
| 63 | 1110 | 11111 |
| 64 | 11110 | 000000 |
A scale other than 2 has never been seen, so it is hard to say how s/r encoding works when s=4, etc. The following is how it might work using s=4, r=2 i.e. a base-4 digit is added each time, meaning two bits added each time.:
Table 5.24. Example of scale and root encoding where scale is greater than 2.
| Value | p | q (base 4) | q (binary) |
|---|---|---|---|
| 0 | 0 | 00 | 0000 |
| 1 | 0 | 01 | 0001 |
| 14 | 0 | 32 | 1110 |
| 15 | 0 | 33 | 1111 |
| 16 | 10 | 00 | 0000 |
| 17 | 10 | 01 | 0001 |
| 30 | 10 | 32 | 1110 |
| 31 | 10 | 33 | 1111 |
| 32 | 110 | 000 | 000000 |
| 33 | 110 | 001 | 000001 |
Of course, this is all wild speculation, since examples with s other than 2 haven't been seen... But the codes do work this way (i.e. prepending a 1 to the prefix multiplies the additive value 'b' by s and adds another log2(s) bits.)
This is all fairly complex, so some examples will be extremely useful here. First a short ficticious example, then an example from the real world.
The following table is a ficticious example of how the words appear in leaf nodes. The storage of words in index nodes is the same as in leaf nodes, except some fields are gone.
Table 5.25. Example leaf node entries
| Stored word | Whole word | Length+1 to add | Position to add at | Context |
|---|---|---|---|---|
| john | john | 5 | 0 | 0 |
| sh | josh | 3 | 2 | 0 |
| ington | joshington | 7 | 4 | 0 |
| joshington | 1 | 10 | 1 (title) |
This example is taken from a copy of windows.chm, the system documentation apparently distributed with some version of Windows 98:
Hex dump of two leaf node entries:
000223d: 02 00 31 ...0...........1 0002240: 00 0a 03 04 00 00 00 00 1d 01 01 01 01 20 04 00 ............. .. 0002250: 00 00 00 03
The fields of these two entries are as follows:
Table 5.26. Example leaf node entries
| Field | 1st entry | 2nd entry |
|---|---|---|
| New length | 2 | 1 |
| Old length | 0 | 1 |
| Word | "1" | |
| Context | 0 | 1 |
| Num WLC ents | 0xA | 1 |
| Offset | 0x403 | 0x420 |
| Unknown | 0 | 0 |
| WLCs length | 0x1D | 3 |
Scanning over to offset 0x403 in the file, we see:
0000403: f9 f4 60 86 b8 ea 6a 00 ed 78 00 2d c0 0000410: f8 d7 28 2c f0 f6 dc c8 ce 66 61 80 87 02 00 00 0000420: f9 f4 40
Broken out, these WLC entries are:
1 <10, 1027, 29>: f9 f4 60 86 b8 ea 6a 00 ed 78 00 2d c0 f8 d7 28
2c f0 f6 dc c8 ce 66 61 80 87 02 00 00
1 (TITLE) <1, 1056, 3>: f9 f4 40
Now, the parameters for the WLC in this file are 2/2, 2/1, 2/5. Here is a quick reference table for the codes:
p value q (bits) 2/1: 0: 0-1 1 10: 2-3 1 110: 4-7 2 1110: 8-15 3 11110: 16-31 4 111110: 32-63 5 2/2: 0: 0-3 2 10: 4-7 2 110: 8-15 3 1110: 16-31 4 11110: 32-63 5 111110: 64-127 6 2/5: 0: 0-31 5 10: 32-63 5 110: 64-127 6 1110: 128-255 7 11110: 256-511 8 111110: 512-1023 9
Let's start with the short one, since it's very simple:
f9 f4 40 => 1111 1001 1111 0100 0100 0000
2/2 Document index: 111110 011111 => 64 + 31 => Document no. 95
2/1 Code count: 0 1 => 1
2/5 Location codes: 0 00100 => 4 => Word no. 4
padding: 0000
So, in document no. 95, word no. 4 is a '1' which is in the title. Now, the ordering of the documents is provided by the #URLTBL and #URLSTR files. Looking up document no. 95 in there (0-based indexing!), we see the file is internet_account.htm, in which, the first non-markup text is:
<title>Dial-Up Networking: Step 1</title> 0: dial 1: up 2: networking 3: step 4: 1
Now, the next one is a little more complicated. I won't go over it in as much detail, but I'll just break it out quickly. It contains 10 entries:
(111110 011111) ( 0 1) ( 0 00110 ) 0000
( 10 00 ) ( 0 1) ( 10 10111 ) 000
( 1110 1010 ) ( 0 1) ( 10 10100 ) 0000000
( 1110 1101 ) ( 0 1) (1110 0000000) 000
( 0 01 ) ( 0 1) ( 10 11100 ) 0000
(111110 001101) ( 0 1) ( 110 010100 ) 0
( 0 01 ) ( 0 1) ( 10 01111 ) 0000
( 11110 11011 ) ( 0 1) ( 110 011001 ) 000
( 110 011 ) (10 0) ( 110 011001 ) ( 10 00011) 0000000
( 10 00 ) ( 0 1) ( 110 000001 ) 0
00000000 00000000
Parsing those entries, we get:
Table 5.27. Example WLC entries.
| Document number | Word numbers |
|---|---|
| 95 | 6 |
| 95+4 = 99 | 55 |
| 99+26 = 125 | 52 |
| 125+29 = 154 | 128 |
| 154+1 = 155 | 60 |
| 155+77 = 232 | 84 |
| 232+1 = 233 | 47 |
| 233+59 = 292 | 89 |
| 292+11 = 303 | 89 and 89+35 = 124 |
| 303+4 = 307 | 65 |
Picking one at random, say, Document no. 303 with 2 hits, we open up windows_netsetup_netwin.htm, from which I've generated a wordlist containing all of the words in order:
0: To(TITLE) 1: set(TITLE) 2: up(TITLE) .. .. 86: client 87: follow 88: steps 89: 1 90: 3 .. 122: follow 123: steps 124: 1 125: 3 126: and ..
And we can see the word '1' shows up in precisely the 89th and 124th spots.
The CHM compiler extracts words from all the input files (those with .h in their names), converts them to lowercase and stores them in the $FIftiMain file.
Words in the leaf and index nodes are made up of the following characters stored as is: 0x01 (buggy), 0-9, a-z, _, 0xDE, 0xFE. Bytes from the input files are converted and stored as per the table below. Character entity references of the form ▼ are truncated to BYTEs and translated as per the table below. Character entity references of the form & are treated as whitespace, except for the the latin characters, which are converted as per the table below.
Table 5.28. Conversions
| Before | After |
|---|---|
| A-Z | a-z |
| 0x8A, 0x9A | s |
| 0x8C, 0x9C | oe |
| 0x9F, 0xDD, 0xFD, 0xFF, Ý, ý, ÿ | y |
| 0xC0-0xC5, 0xE0-0xE5, À, À, Á, Â, Ã, Ä, Å, à, á, â, ã, ä, å. | a |
| 0xC6, 0xE6, Æ, æ | ae |
| 0xC7, 0xE7, Ç, ç | c |
| 0xC8-0xCB, 0xE8-0xEB, È, É, Ê, Ë, è, é, ê, ë | e |
| 0xCC-0xCF, 0xEC-0xEF, Ì, Í, Î, Ï, ì, í, î, ï | i |
| 0xD0, Ð | d |
| 0xD1, 0xF1, ñ, Ñ | n |
| 0xD2-0xD8, 0xF0, 0xF2-0xF8, ð, Ò, Ó, Ô, Õ, Ö, Ø, ò, ó, ô, õ, ö, ø | o |
| 0xD9-0xDC, 0xF9-0xFC, Ù, Ú, Û, Ü, ù, ú, û, ü | u |
| 0xDF, ß | ss |
| þ | 0xFE |
| Þ | 0xDE |
These conversons may depend on the system codepage, character set, font and language set in the HHP file, but I'm just guessing here.
There are a few known bugs that are described in the following few paragraphs.
An 0x01 in a word causes the first whitespace character at the end of the word to be included in the word and if the next character is non-whitespace the word is joined to the next word. If the word begins with 0-9 then the word is terminated before the 0x01 and a new word begins at the 0x01. This bug affects the fields in the initial header. For example: abcd0x1efghi-foobar is converted to abcd0x1efghi-foobar. abcd0x1efghi- foobar is converted to abcd0x1efghi- and foobar. 0bcd0x1efghi-foobar is converted to 0bcd and 0x1efghi-foobar. 0bcd0x1efghi- foobar is converted to 0bcd, 0x1efghi- and foobar.
Weird bug where if the word is 16 characters in length then the word is doubled plus the first 7 chars in length.
There is a weird feature that if a word starts with 0-9 then it may contain multiple periods (0x2E = '.') or commas (0x2C = ',') embedded in the word before the non-period, non-comma word terminating character. I think this feature is so that the user can search for version numbers or numbers with a decimal point or thousands separator in them. Note that commas are removed from the word, while periods are not. For example v1.1.234.5......,6 will become v1 and 1.234.5......6.
There is a weird bug involving words ending in single quote (') being forgotten when the same word is also normal and also ending in a period (.).
There are probably many more hidden bugs and features in the word converter (I think its the the ITIR.StdWordBreaker class in ITIRCL.DLL).
From the name and the number of GUIDs present I guess it has something to do with ActiveX objects. Seems like it can be deleted without major consequence.
Table 5.29. The format of the $OBJINST header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | 0x04000000 (unknown) |
| 4 | DWORD | Number of entries |
This is followed by an listing, and each listing entry is as follows
Table 5.30. The format of the $OBJINST listing entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Offset of the entry in this file |
| 4 | DWORD | Length of the entry |
The listing is followed by the entries one after another at offsets specified in the listing.
There are 2 known types of entries. The first seems to be made up of up to 3 different sub entries. The second is a 36 BYTE structure.
Table 5.31. The first entry
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | GUID | {4662DAAF-D393-11D0-9A56-00C04FB68BF7} |
| 0x10 | DWORD | 0x04000000 (unknown) Possibly a big-endian version number of the class that the GUID refers to. |
| 0x14 | DWORD | Unknown. Methinks bitflags that somehow affect the size of entries that have the 0x04000000 DWORD, like each bit specifies the presence/absence of a specific subentry. |
| 0x18 | DWORD | Windows code page identifier (usually 1252 - Windows 3.1 US (ANSI)) |
| 0x1C | DWORD | LCID from the HHP file. |
| 0x20 | BYTEs | Unknown |
| +0 | Entries | |
I haven't been able to find any files without the data for bits 0 & 1 so I can't really say exactly how big the header is and which bytes are part of the bit 0 block and which are part of the bit 1 block. Together, though, bits 0 & 1 account for a large bulk of repeatedly increasing byte blocks of 10 bytes each, plus something else at the end. I suspect that the repeats are for bit 0 and the stuff at the end is bit 1. As to the function of these two bits blocks, well there are no GUIDs and no other clues, so who knows.
Table 5.32. bit 2. Only present when "Full text search stop list file" has been specified in the HHP.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | char[4] | ""(\0 |
| 4 | DWORD | Length in bytes of the entries not including the last zero word. |
| 8 | BYTE[32] | 0 (unknown) |
| 0x28 | Entries. The last entry has a zero length word. | |
Table 5.33. bit 2 entries
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | Length of the word |
| 2 | char[length] | ANSI/UTF-8 string from the stop list file, may be uniqified & sorted reverse alphabetically. Not NT. |
Table 5.34. bit 3
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | GUID | {8FA0D5A8-DEDF-11D0-9A61-00C04FB68BF7} |
| 0x10 | DWORD | 0x04000000 (unknown) Possibly a big-endian version number of the class that the GUID refers to. |
| 0x14 | DWORD | 1 (unknown) |
| 0x18 | DWORD | Windows code page identifier (usually 1252 - Windows 3.1 US (ANSI)) |
| 0x1C | DWORD | LCID from the HHP file. |
| 0x20 | DWORD | 0 (unknown) |
Table 5.35. The second entry
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | GUID | {4662DAB0-D393-11D0-9A56-00C04FB68B66} |
| 0x10 | DWORD | 666 (May represent the version of the class that the GUID refers to) |
| 0x14 | DWORD | Windows code page identifier (usually 1252 - Windows 3.1 US (ANSI)) |
| 0x18 | DWORD | LCID from the HHP file. |
| 0x1C | DWORD | Unknown. Almost always 10031. Also 66631 (accessib.chm from the MSDN). |
| 0x20 | DWORD | 0 (unknown) |
The files in the $WWAssociativeLinks and $WWKeywordLinks directories have the same formats. The maximum total length (including parents) of an entry in one of these files is 488 characters (including NT). HHW complains about and refuses to output any that are greater than this length.
The $WWKeywordLinks dir specifies the contents of the Index navigation pane & the $WWAssociativeLinks dir specifies the Alinks.
In CHW files this is named BTREE and in CHI/CHM files it is named BTree.
This file has a 76 byte header, then 2048 byte blocks. First come all the listing blocks, then all the index blocks. This file is similar to the directory entries in the ITSF format, except that the index blocks are at the end instead of interspersed with the listing blocks. All block indices below are zero based. This file forms a tree, with the last (index mostly) block being the root of the tree. If there is more than one level of index blocks then the root block will have two children; the first in the block header and the second in the entry. WARNING: just as in the ITSF directory there can be garbage in the free space, so respect that first WORD and use it. I'm not yet sure how the listing blocks are split up, though it is probably the same as the ITSF directory (space filling).
Table 5.36. The format of the BTree header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | char[2] | ;) (0x3B 0x29) (signature)[a] |
| 2 | WORD | [a]Flags. Bit 0x2 always 1. Bit 0x0400 1 if directory?? (this is always on) |
| 4 | WORD | Size of the blocks (2048) |
| 6 | BYTE[16] | Always X44. [a]It is likely to be a string describing format of data
'L' = DWORD (indexed)
'F' = NUL-terminated string (indexed)
'i' = NUL-terminated string (indexed)
'2' = WORD
'4' = DWORD
'z' = NUL-terminated string
'!' = DWORD count value, count/8 * record
DWORD filenumber
DWORD TopicOffset
|
| 0x16 | DWORD | 0 (unknown) |
| 0x1A | DWORD | Index of the last listing block in the file. |
| 0x1E | DWORD | Index of the root block in the file. |
| 0x22 | DWORD | -1 (unknown) |
| 0x26 | DWORD | Number of blocks |
| 0x2A | WORD | The depth of the tree of blocks (1 if no index blocks, 2 one level of index blocks, ...) |
| 0x2C | DWORD | Number of keywords in the file. |
| 0x30 | DWORD | Windows code page identifier (usually 1252 - Windows 3.1 US (ANSI)) |
| 0x34 | DWORD | LCID from the HHP file. |
| 0x38 | DWORD | 0 if this a BTREE and is part of a CHW file, 1 if it is a BTree and is part of a CHI or CHM file |
| 0x3C | DWORD | Unknown. Almost always 10031. Also 66631 (accessib.chm, ieeula.chm, iesupp.chm, iexplore.chm, msoe.chm, mstask.chm, ratings.chm, wab.chm). |
| 0x40 | DWORD | 0 (unknown) |
| 0x44 | DWORD | 0 (unknown) |
| 0x48 | DWORD | 0 (unknown) |
[a] These were guessed from the documentation provided with helpdeco by Manfred Winterhoff. | ||
Table 5.37. The format of the BTree listing blocks header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | Length of free space at the end of the block. |
| 2 | WORD | Number of entries in the block. |
| 4 | DWORD | Index of the previous block. -1 if this is the first listing block. |
| 8 | DWORD | Index of the next block. -1 if this is the last listing block. |
Table 5.38. The format of the BTree listing block entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WCHARs | Value of the first Name entry from the HHK UTF-16/UCS-2. If this is a sub-keyword, then this will be all the parent keywords, including this one, separated by ", ". UTF-16/UCS-2 NT. |
| +0 | WORD | 2 if this keyword is a See Also keyword, 0 if it is not. |
| +2 | WORD | Depth of this entry into the tree. |
| +4 | DWORD | Character index of the last keyword in the ", " separated list. |
| +8 | DWORD | 0 (unknown) |
| +0xC | DWORD | Number of Name, Local pairs |
| +0x10 | DWORDs or WCHARs | DWORDs:Index into the #TOPICS file. UTF-16/UCS-2 NT string: The value of the See Also string. |
| +0 | DWORD | Mostly 1 (unknown) |
| +4 | DWORD | Zero based index of this entry in the file (not block). Increments by 13 (each entry is 13 more than the last). |
Table 5.39. The format of the BTree index blocks header.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | Length of free space at the end of the block. |
| 2 | WORD | Number of entries in the block. |
| 4 | DWORD | Index of a child block. |
Table 5.40. The format of the BTree index block entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WCHARs | Value of the first Name entry from the HHK. If this is a sub-keyword, then this will be all the parent keywords, including this one, separated by ", ". UTF-16/UCS-2 NT. |
| +0 | WORD | 2 if this keyword is a See Also keyword, 0 if it is not. |
| +2 | WORD | Depth of this entry into the tree. |
| +4 | DWORD | Character index of the last keyword in the ", " separated list. |
| +8 | DWORD | 0 (unknown) |
| +0xC | DWORD | Number of Name, Local pairs |
| +0x10 | DWORDs or WCHARs | DWORDs:Index into the #TOPICS file. UTF-16/UCS-2 NT string: The value of the See Also string. |
| +0 | DWORD | Index of a child block. If it is a listing block then it is the one that starts with the keyword at the start of this entry |
In CHW files this is named DATA and in CHI/CHM files it is named Data.
This file contains entries that are 13 bytes in length. All known entries have thus far contained the following bytes: 00000000 05000000 80000000 00. AFAICS this file is useless.
In CHW files this is named MAP and in CHI/CHM files it is named Map.
Begins with a WORD indicating the number of entries in the file (also the number of listing blocks in the BTree file). Each entry is 2 DWORDs. The first is a cumulative sum of the number of keywords in the BTree listing blocks & the second is a consecutively increasing index number. Both start at zero.
The file begins with a WORD indicating the number of entries.
Each entry has the following format:
Table 5.41. The format of the $HHTitleMap entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | WORD | Length of the file stem. |
| 2 | BYTEs | File stem. ANSI/UTF-8 string. Not NT. |
| +0 | DWORD | Unknown. |
| +4 | DWORD | Unknown. Same value as previous DWORD. |
| +8 | DWORD | LCID of the specified file. |
The file begins with a WORD indicating the number of entries.
Each entry is 68 BYTEs in length and has the following format:
Table 5.42. The format of the $TitleMap entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | BYTE[25] | File stem. ANSI/UTF-8 NT fixed length string. |
| 0x19 | BYTE[25] | Unknown. Seems to be RAM litter, but contains paths, file names, zero bytes, DWORDs and mixtures. |
| 0x32 | WORD | An index number that begins at 1 and is incremented by 1 for each entry. |
| 0x34 | DWORD | Unknown. |
| 0x38 | DWORD | Unknown. Same value as previous DWORD. |
| 0x3C | DWORD | LCID of the specified file. |
| 0x40 | DWORD | Number of topic nodes including the contents & index files in the specified file. |
It is a cache of user customized bits of the windowtype entry from the #WINDOWS file of the \Path\file.chm CHM file.
Table 5.43. The format of the windowtype entries.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD | Size of the file in bytes (44) |
| 4 | Signed DWORD | Position of the left edge of the window. |
| 8 | Signed DWORD | Position of the top edge of the window. |
| 0xC | Signed DWORD | Position of the right edge of the window. |
| 0x10 | Signed DWORD | Position of the bottom edge of the window. |
| 0x14 | DWORD | Width of the navigation pane in pixels. |
| 0x18 | DWORD | Non-zero if search highlight is on. |
| 0x1C | DWORD | Unknown. Not font size, printing options or show state. |
| 0x20 | DWORD | Non-zero if there is no text of the toolbar buttons. |
| 0x24 | DWORD | Non-zero if the navigation pane is initially closed. |
| 0x28 | DWORD | Which navigation tab is currently open. |
UTF-16/UCS-2 NT string. Each search item is separated by a UTF-16/UCS-2 Line Feed character. The string is followed by an unknown WORD.
DWORD. Only the lowest 3 bits are used, the other bits are unknown. is controlled by bit 0. is controlled by bit 1. is controlled by bit 2. Note that since previous search results are not stored anywhere as yet HH will uncheck the checkbox even if its bit is on. IMHO this is a bug: HH should automatically search the whole file if there are no previous results and the checkbox is checked.
A DWORD indicating the number of favourites stored for the \Path\file.chm CHM file.
An NT UTF-16/UCS-2 string showing the topic name of bookmark number n (n is zero based).
An NT UTF-16/UCS-2 string showing the URL of bookmark number n (n is zero based). It is a fully qualified path into the \Path\file.chm CHM file.
A set of ANSI/UTF-8 NT strings indicating which internal files have been deleted in the new file. Names use backslash (\) instead of forward slash (/) & don't have an initial slash.
Table 5.44. The format of the #KEY_DATA file.
| Offset | Type | Comment/Value |
|---|---|---|
| 0 | DWORD[8] | Unknown. |
| 0x20 | DWORD | Length of the name of the old chm. |
| 0x24 | BYTEs | Name of the old chm. ANSI/UTF-8 NT. |
|
|
 |
|
| 5.2. ITSF format |  |
5.4. CHS format |